今回も前回に引き続き、Pythonでの画像処理を紹介していきたいと思います。「細胞種を機械学習で判別する!」( https://lp-tech.net/articles/e0mRJ )でも軽く触れましたが、画像の水増しについて書きたいと思います。
画像を利用した機械学習では大量の画像をもとにニューラルネットワークに学習を行わせますが、しばしば大量の画像を用意するのが難しいときもあり、少ない画像を最大限に活用したいというシチュエーションは比較的多く存在すると思います。そこで、画像の水増し、Data Augmentationと呼ばれる方法になりますが、学習に使う画像に変形を加えたり、ノイズを加えたり、明るさを変えたりといった処理を行う方法を紹介します。学習画像に様々な処理を行うことで認識がロバストになるというメリットがあります。
画像を利用した機械学習では大量の画像をもとにニューラルネットワークに学習を行わせますが、しばしば大量の画像を用意するのが難しいときもあり、少ない画像を最大限に活用したいというシチュエーションは比較的多く存在すると思います。そこで、画像の水増し、Data Augmentationと呼ばれる方法になりますが、学習に使う画像に変形を加えたり、ノイズを加えたり、明るさを変えたりといった処理を行う方法を紹介します。学習画像に様々な処理を行うことで認識がロバストになるというメリットがあります。
ヒストグラム
8ビットのグレースケール画像について言えば、画像の中には真っ黒な画素(0)から真っ白な画素(255)までの間の256段階の階調の値が存在します。それをヒストグラムにすると、画像中の画素値の分布がわかります。認識をロバストにする上でヒストグラムの形状が学習画像と、実際に判別させたい画像で大きく異なっていると不都合です。今回は学習画像のヒストグラムを様々に変える方法と、学習画像のヒストグラムを正規化し、実際に判別させたい画像の前処理としてヒストグラムの正規化を前提とする2つの解決策を示します。
学習画像のヒストグラムを様々に変える
学習前の画像のヒストグラムを様々に変えることで、学習済みのモデルが様々なヒストグラム形状を持つ画像に対応できるようにしておこうという考え方です。
ヒストグラムの変え方は色々考えられると思いますが、簡単なものだけ紹介します。
import numpy as np import cv2 src = cv2.imread('src.png',0) img = src*1.2 #輝度値が2倍になる cv2.imwrite("1.png",img) img = src + 40 #輝度値のベースが40上がる cv2.imwrite("2.png",img) img = (img-np.mean(src))/np.std(src)*32+120 #標準偏差32,平均120に変更 cv2.imwrite("3.png",img) img = (img-np.mean(src))/np.std(src)*16+120 #標準偏差16,平均120に変更 cv2.imwrite("4.png",img)
hist.py
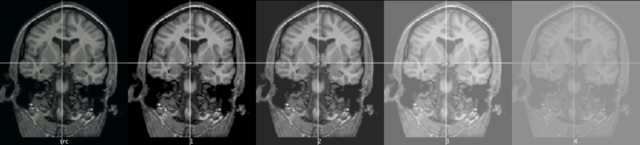
なお、numpyで255以上の画素値を持つ画像をpngなどでcv.imwriteで保存しようとするとおかしな画像が保存されてしまいます。そのような場合には255以上の画素値は255になるように処理します。
img = np.minimum(img,255)minimum.py
ヒストグラムを正規化する
学習に用いる画像を予め処理し、ヒストグラムの形状を整えておく方法です。この方法を使った場合には、学習済みモデルで推論を行う場合にも画像に同様の前処理を前提とするので注意が必要です。学習に用いた画像に行った処理と推論の対象画像に行う処理が別物のだと期待通りの結果は得られません。
ヒストグラムを正規化する方法では学習の対象の画像の枚数を闇雲に増やすことがないのでよく使われます。一番簡単な正規化の方法は、画素値の分布の平均と分散を揃える方法でしょう。PythonとOpenCVでは、下のようなコードで実現できます。
img = (img - np.mean(img))/np.std(img)*16+64
norm.py

via cvtech.cc





 Mochizuki
Mochizuki




