今回は,前回(Part1.)に引き続き, 『パターン認識と機械学習』に沿って,機械学習の入門的なお話をまとめていきます.
前回は第1章の1.1節まで進めましたから,次は1.2節の「確率論」を…と進めたいところですが, 大人の事情によりいったん飛ばし,1.3節・1.4節のお話を先にしたいと思います.
【いかに良いモデルを選ぶか ~1.3節~】
前回お話した内容を振り返ってみましょう.
前回は,「多項式フィッティング」という題材で
ということを述べました. モデルが単純すぎるとうまく訓練データを説明できませんし, かといってモデルが複雑であればあるほど良いわけでもなく, 複雑すぎると過学習と呼ばれる現象が起きるのでした. 過学習が生じると,訓練データにはとてもよく適合するものの, 訓練データの誤差に引きずられ,テストデータにはかえって合致しにくくなってしまいます.
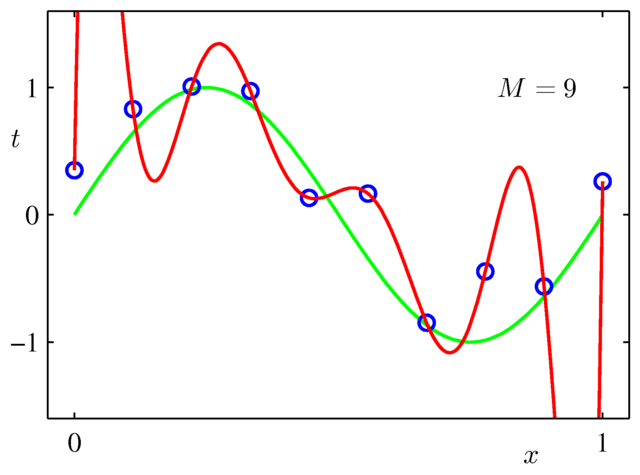
過学習を起こしている例
また,過学習を避ける方法の一つとして,正則化項を導入するものがありました. これは,「訓練データとのずれ」に加えて「モデルの複雑さ」を評価関数に導入することで, 訓練データとにある程度合致し,なおかつ複雑すぎないモデルを達成しようという狙いです. 具体的には, \begin{align} \tilde{E}(\bm{w})&={\color{red}{\dfrac{1}{2}\sum_{n=1}^N\bigl(y(x_n,\bm{w})-t_n\bigr)^2}} +{\color{blue}{\dfrac{\lambda}{2}\|\bm{w}\|^2}}\\ \text{ただし,}\quad\|\bm w\|^2&={w_0}^2+{w_1}^2+\cdots+{w_M}^2 \end{align} という式を最小化するのでした. 右辺の第1項が「訓練データとのずれ(二乗誤差)」を表し, 第2項が「モデルの複雑さ(多項式の係数の二乗和)」を表しています.
ここで重要なのは $\lambda$ というパラメータです. これは正の値を取り,「ずれと複雑さ,どちらを減らすことを重視するか」を決める役割を果たします.
$\lambda$が小さければ小さいほど, 「訓練データとのずれを少なくする」ことを重視するようになります. たとえば$\lambda=0$のとき,$\|\bm{w}\|^2$ の項は消えてしまい, 「モデルはいくら複雑でもいいから,ひたすらずれを最小化する」 ようになります.これでは実質正則化項はないに等しいので,過学習を起こしやすくなります. 逆に,$\lambda$ が大きければ大きいほど, 「単純なモデルにする」ことを重視するようになります. 特に $\lambda\to\infty$ のとき, 「訓練データとのずれはどうでもいいから,単純なモデルを選択する」 ようになります.これでは本末転倒ですね.
結局,$\lambda$は大きすぎず小さすぎず, 丁度良いところで留めるのが,最も効率の良い学習法ということになります. 月並みな言葉でまとめると, 「物事なんでもバランスが大事」ということです. それでは, バランスの良い学習を行うために私たちは何をすればよいのでしょうか.
多項式フィッティングでは, 多項式の次数というパラメータがモデルの複雑さを表していました. また上で述べた通り,最適化項を導入した場合は $\lambda$ がモデルの複雑さを表していました. こういったパラメータは,はたしていくつにするのがふさわしいのでしょうか. 最適なパラメータの値を知らなければ, いくら最適化項などの手法を知っていたところで, 学習不足や過学習の問題から逃れることはできません.
この「パラメータはいくつがふさわしいか問題」の厄介なところは, 今まで述べたような単純な学習法では, 訓練データだけでは(それが良いパラメータかどうか)判別できない という点です. 学習不足のときはともかく,過学習を起こしているときは, モデルは「訓練データ」にはよく適合するのですから, 「訓練データとの適合度合い」は良いパラメータかどうかの指標にはなりません. 学習の結果うまくいくかどうかは,「ふたを開けてみなければ」, つまり,実際にテストデータに当てはめてみなければ分からないのです.
単純な解決法:確認用集合の用意
最も単純な解決方法は, 確認用集合(validation set) を用意することです.
前回,機械学習で扱うデータには, 「訓練データ」と「テストデータ」の2種類があると話しました. まずは正解の分かっている訓練データを用いて学習し, 正解の不明なテストデータに当てはめてみる,というのが機械学習の基本の流れです.
しかし,訓練データだけでは過学習が起きているか判別するのが困難です. そこで,今まで全て「訓練データ」として使っていたものの一部を「検証用データ」とし, 検証用データに対する当てはまり度合いをもとに過学習が起きていないか判別するという方法が考えられます. この検証用データを確認用集合といいます. 確認用集合で当てはめた結果を見て多項式の次数や $\lambda$ を調整し, もっとも結果の良いものをモデルとして採用するとよいでしょう.
しかし,この方法を行いすぎると, 今度はその確認用集合についても過学習を起こしてしまうことがあるといわれています. つまり,「訓練データ・検証用データにはよく適合するが,肝心のテストデータに適合しない」 という現象が起きてしまうおそれがあります.
また,正直なところ,多くの場合データというのは貴重なものです. できるかぎりデータはモデルを作るときに活かしたい, つまり,訓練に用いたいという欲求があります. とはいえ,確認用集合が小さすぎると, 今度は性能の予測結果が確認用集合のチョイスに大きく左右され, 安定した性能予測を得ることができません.
交差確認
貴重なデータはなるべく訓練にまわしたい, しかし確認用集合もたくさん欲しい…… こういったジレンマを解決する手段の一つが交差確認(cross-validation)です.
仕組みは単純です.
- データを$S$個のグループに分割する.
- グループを1つとってそれを「確認用集合」とし,残りを訓練データに使って学習する. その性能をスコアとして算出する.
- 上で選んだものとは別のグループを選び,同様のことを行う. これを全グループについて繰り返す.
- 最後にすべての場合におけるスコアを平均する
というものです. たとえるなら,小学校の日直や掃除当番のようなものです. 掃除当番を決めるとき, クラスを$S$個の班に分けてから週ごとにかわるがわる当番を担当するように, 順々に「モデルの評価当番」を設定して評価していくのです. 下の図を参照してください.

交差確認の概念図
1. 得られたデータを4つのグループに分ける.
2. 3つのグループをモデルの訓練に用い,残りの1つでモデルを評価する.
3. 評価する集合を変えてステップ2を繰り返す.
4. 全ての場合について評価出来たら,そのすべての性能のスコアを平均する.
特にデータ数$N$が少ないときは, 評価用の集合の要素を1つにし,$N$個のグループを作って交差確認を行う, 通称「LOO法(1個抜き法,Leave-one-out method)」が推奨されます (人数の少ないクラスでは日直を1人にするようなものです).
交差確認はデータを訓練にも確認にも回せるため,上記のジレンマを解決してくれます. しかし,グループの数$S$を大きくすると, それに比例して訓練を行う回数が増えてしまうという欠点があります. また,最初に述べた多項式フィッティングの例のように単純なモデルでは問題になりませんが, 中には,「モデルの複雑さ」を表すのに複数のパラメータを要する場合があります. 複数のパラメータを場当たり的に試すとなると, 最適なパラメータを見つけるまでに必要な訓練回数が非常に多くなってしまうかもしれません.





 最上 伸一
最上 伸一






9次の多項式でフィッティングしたもの.
訓練データが10個(青丸で示した)の場合,赤線のようなフィッティング結果が得られる.
これは青丸(訓練データ)を完全に再現できているものの,緑の線からはかけ離れており,テストデータにはほぼ合致しそうもない.
過学習を起こしている典型例である.