前回は、白血球(好中球、好酸球、単球)の顕微鏡画像(90枚)を用いて、これら3種類の分類を行いました。画像の水増し(Data Augmentation)や交差検証(KFold)などの精度良く分類できる手法を紹介しました。
今回は、上記の手法に加え、転移学習(Transfer Learning)と呼ばれる学習済みのモデルを利用する手法を試します。画像は前回と同じものを用いました。
今回は、上記の手法に加え、転移学習(Transfer Learning)と呼ばれる学習済みのモデルを利用する手法を試します。画像は前回と同じものを用いました。
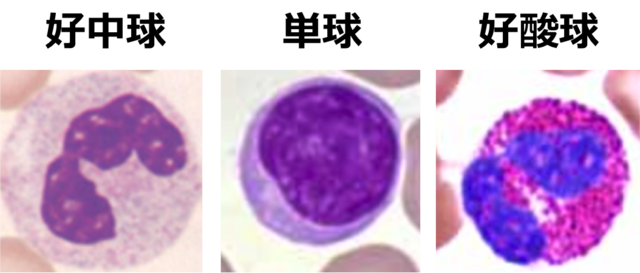
図1. 分類する白血球の例(3種類)
3種類の白血球(好中球、単球、好酸球)の顕微鏡画像それぞれ30枚(計90枚)を用いて転移学習を用いた分類を行った。
転移学習(Transfer Learning)
畳み込みニューラルネット(CNN)では、層間の結合重みが最適化されることによって、学習モデルが作られますが、既に学習済みのモデルをCNNに用いる手法を転移学習と呼びます。
公開されている学習済みモデルの多くは、ImageNetと呼ばれる大規模な画像データセット(1000クラス)を用いた画像分類の競技会(ILSVRC)で用いられたモデルで、AlexNet, GoogLeNet, VGG, ResNet等が挙げられます。中でもResNetは、2015年のILSVRCで優勝したモデル(152層)で画像判定エラー率が約4%と、人間の識別精度を上回っています。
Kerasでは、これらの学習済みモデルの構造と重みを自動的にダウンロードして使えるようになっており、自分でモデル構造を書いたり、重み情報をダウンロードする必要もありません(但し、Keras1.2.0以降のversionに限る)。また、モデルの学習を最初から行う必要がないので、GPUなしのPCでも十分短時間で計算できます。
今回は、オックスフォード大学で開発された「VGG-16」と呼ばれるモデル(畳み込み層と全結合層(計16層)を含むCNN)を学習済みモデルとして用いて転移学習を行いました(図2)。
公開されている学習済みモデルの多くは、ImageNetと呼ばれる大規模な画像データセット(1000クラス)を用いた画像分類の競技会(ILSVRC)で用いられたモデルで、AlexNet, GoogLeNet, VGG, ResNet等が挙げられます。中でもResNetは、2015年のILSVRCで優勝したモデル(152層)で画像判定エラー率が約4%と、人間の識別精度を上回っています。
Kerasでは、これらの学習済みモデルの構造と重みを自動的にダウンロードして使えるようになっており、自分でモデル構造を書いたり、重み情報をダウンロードする必要もありません(但し、Keras1.2.0以降のversionに限る)。また、モデルの学習を最初から行う必要がないので、GPUなしのPCでも十分短時間で計算できます。
今回は、オックスフォード大学で開発された「VGG-16」と呼ばれるモデル(畳み込み層と全結合層(計16層)を含むCNN)を学習済みモデルとして用いて転移学習を行いました(図2)。

図2. VGG-16のモデル構造
畳み込み層と全結合層(計16層)を含むCNN。畳み込み層の下の数字は畳み込みフィルタ数を表す。畳み込みフィルタの大きさは全て3×3。
全結合層は、4096ユニット2層+クラス分類用の1000ユニット1層からなる。
全結合層は、4096ユニット2層+クラス分類用の1000ユニット1層からなる。
モデルの再調整(Fine-tuning)
学習済みモデルが使えるとは言え、それはあくまでも、ImageNetと呼ばれる大規模な画像データセットを学習したものです。そのため、分類したい画像のカテゴリーが、ImageNetの中に含まれていない場合も十分あり得ます。例えば、今回のような白血球の画像などはImageNetには含まれていません。
また、ImageNetでは1000種類に分類するため、上に挙げた学習済みモデルの出力層のユニット数は1000に設定されています。しかし、今回は3種類の白血球を分類したいので出力層のユニット数は3に変更する必要があります。
このような内容をふまえると、学習済みモデルの重みをそのまま用いるのではなく、部分的にそれらを初期値として用い、分類したい画像データに合わせて細かく再調整(チューニング)して学習させることが理想的です。この手法はFine-tuningと呼ばれ、今回のような100枚に満たないような少ない画像数でも実行可能です。
今回、全結合層はVGG-16学習済みモデル(4096ユニット2層+クラス分類用の1000ユニット1層)を用いず、自作の構造(256ユニット1層+クラス分類用の3ユニット1層)を用いました。モデル重みのFine-tuning(再調整)を行った領域は、全結合層とその一つ前の畳み込み層(3層)+プーリング層のセットで、それより浅い層では学習済みのモデル重みをそのまま用いました(図3)。深い層をFine-tuningに用いた理由は、CNNでは深い層ほど学習データに特化した特徴が抽出される傾向にあるためです。
上記のように、VGG-16モデルのFine-tuningを行う部分のコードを下に記します。
また、ImageNetでは1000種類に分類するため、上に挙げた学習済みモデルの出力層のユニット数は1000に設定されています。しかし、今回は3種類の白血球を分類したいので出力層のユニット数は3に変更する必要があります。
このような内容をふまえると、学習済みモデルの重みをそのまま用いるのではなく、部分的にそれらを初期値として用い、分類したい画像データに合わせて細かく再調整(チューニング)して学習させることが理想的です。この手法はFine-tuningと呼ばれ、今回のような100枚に満たないような少ない画像数でも実行可能です。
今回、全結合層はVGG-16学習済みモデル(4096ユニット2層+クラス分類用の1000ユニット1層)を用いず、自作の構造(256ユニット1層+クラス分類用の3ユニット1層)を用いました。モデル重みのFine-tuning(再調整)を行った領域は、全結合層とその一つ前の畳み込み層(3層)+プーリング層のセットで、それより浅い層では学習済みのモデル重みをそのまま用いました(図3)。深い層をFine-tuningに用いた理由は、CNNでは深い層ほど学習データに特化した特徴が抽出される傾向にあるためです。
上記のように、VGG-16モデルのFine-tuningを行う部分のコードを下に記します。

図3. VGG-16のFine-tuning
全結合層は自作の構造(256ユニット1層+クラス分類用の3ユニット1層)を用いた。
全結合層とその一つ前の畳み込み層(3層)+プーリング層のセットにおいてFine-tuningを行い、モデル重みを再調整した。それより浅い層におけるモデル重みは固定した。
全結合層とその一つ前の畳み込み層(3層)+プーリング層のセットにおいてFine-tuningを行い、モデル重みを再調整した。それより浅い層におけるモデル重みは固定した。
from keras.applications.vgg16 import VGG16 from keras.models import Sequential from keras.layers import Input, Dense, Dropout, Activation, Flatten from keras.optimizers import SGD # VGG-16モデルの構造と重みをロード # include_top=Falseによって、VGG16モデルから全結合層を削除 input_tensor = Input(shape=(3, img_rows, img_cols)) vgg16_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # 全結合層の構築 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:])) top_model.add(Dense(256)) top_model.add(Activation("relu")) top_model.add(Dropout(0.5)) top_model.add(Dense(nb_classes)) top_model.add(Activation("softmax")) # 全結合層を削除したVGG16モデルと上で自前で構築した全結合層を結合 model = Model(input=vgg16_model.input, output=top_model(vgg16_model.output)) # 図3における14層目までのモデル重みを固定(VGG16のモデル重みを用いる) for layer in model.layers[:15]: layer.trainable = False # モデルのコンパイル model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True), metrics=['accuracy'])
vgg16_finetuning.py
転移学習を用いた分類の結果
前回は、小さなCNN(畳み込み層2層)を用いて90%の精度で分類が行われました。今回は、学習済みのVGG-16のモデル重みの利用とその再調整(Fine-tuning)によって、どの程度精度が向上するかを見てみました。
前回と同じく、5分割のKfoldを用いた5パターンのモデルによる推測結果の平均は以下の通りです(推測確率の算出にはval_lossが最小となる各モデル重みを用いました)。
loss(訓練画像の損失): 0.03 accracy(訓練画像の精度):0.99
val_loss(評価画像の損失):0.06 val_accracy(評価画像の精度):0.99
評価画像を含めた精度(val_acuracy)は99%となり、精度の飛躍的な向上が見られました。
訓練画像と評価画像以外のテスト画像12枚(3種類をそれぞれ4枚ずつ)を用いて、個別に予測確率を計算したものを図4に示します。テスト画像の数が少ないので統計的には何とも言えませんが、12/12 = 100(%)の確率で正しい認識を示しました。
前回と同じく、5分割のKfoldを用いた5パターンのモデルによる推測結果の平均は以下の通りです(推測確率の算出にはval_lossが最小となる各モデル重みを用いました)。
loss(訓練画像の損失): 0.03 accracy(訓練画像の精度):0.99
val_loss(評価画像の損失):0.06 val_accracy(評価画像の精度):0.99
評価画像を含めた精度(val_acuracy)は99%となり、精度の飛躍的な向上が見られました。
訓練画像と評価画像以外のテスト画像12枚(3種類をそれぞれ4枚ずつ)を用いて、個別に予測確率を計算したものを図4に示します。テスト画像の数が少ないので統計的には何とも言えませんが、12/12 = 100(%)の確率で正しい認識を示しました。

図4. テスト画像の分類結果
(上段)好中球(Neutrophil),
(中段)単球(Monocyte),
(下段)好酸球(Eosinophil)
のそれぞれ4つのテスト画像に対する予測確率を示す。
それぞれの値は、Kflodによって作られた5パターンのモデルそれぞれから計算された推測確率の平均値。3種類の全てのテスト画像で、正しい推定が行われた。
(中段)単球(Monocyte),
(下段)好酸球(Eosinophil)
のそれぞれ4つのテスト画像に対する予測確率を示す。
それぞれの値は、Kflodによって作られた5パターンのモデルそれぞれから計算された推測確率の平均値。3種類の全てのテスト画像で、正しい推定が行われた。
今回は、VGG-16という学習済みのCNNモデルの転移学習を用いて白血球画像の分類を行いました。90枚という少ない画像数ながら、前回の小さなCNNのモデルによる精度(90%)から飛躍的に伸び、99%の精度で分類が可能になりました。
今回の画像は、ImageNetのカテゴリーに含まれていない画像にも関わらず転移学習がうまくいきましたが、どんな画像でも転移学習で精度が上がるわけではないことには注意が必要です。
学習用と評価用のコードを下に載せましたので参考にしてください。
【参考URL / 文献】
[1] 実装ディープラーニング,藤田一弥, 高原 歩,オーム社.
[2] http://aidiary.hatenablog.com/entry/20170110/1484057655
[3] https://lp-tech.net/articles/Y56uo, Deep learningで画像認識⑦〜Kerasで畳み込みニューラルネットワーク vol.3〜
今回の画像は、ImageNetのカテゴリーに含まれていない画像にも関わらず転移学習がうまくいきましたが、どんな画像でも転移学習で精度が上がるわけではないことには注意が必要です。
学習用と評価用のコードを下に載せましたので参考にしてください。
【参考URL / 文献】
[1] 実装ディープラーニング,藤田一弥, 高原 歩,オーム社.
[2] http://aidiary.hatenablog.com/entry/20170110/1484057655
[3] https://lp-tech.net/articles/Y56uo, Deep learningで画像認識⑦〜Kerasで畳み込みニューラルネットワーク vol.3〜
from __future__ import print_function import os import struct import numpy as np from keras.applications.vgg16 import VGG16 from keras.models import Sequential, Model from keras.layers import Input, Dense, Dropout, Activation, Flatten from keras.optimizers import SGD from keras.callbacks import EarlyStopping, ModelCheckpoint from keras.utils import np_utils from sklearn.model_selection import KFold from sklearn.model_selection import train_test_split from keras.preprocessing.image import ImageDataGenerator # 各種パラメータ nb_classes = 3 # 分類するクラス数 nb_epoch = 50 # 最適化計算のループ回数 batch_size = 32 # 計算効率化のために分割された訓練データの1グループあたりのデータ数 img_rows, img_cols = 100, 100 # 入力画像の縦横pixel数 all_filenumber = 90 # 訓練用 & 評価用画像の数 bytesize = 3 # 画像のbyte数(24bit = 3byte) pixelnum = img_rows*img_cols index = 0 # 配列の確保 X_train_binary = [0 for j in range(bytesize*pixelnum*all_filenumber)] X_train_int = [0 for j in range(bytesize*pixelnum*all_filenumber)] y_train_int = [] # 画像&ラベルデータの読み込み filenameX_train = "blood_total.raw" filenameY_train = "blood_total_label.txt" path1 = "/Users/satoshi/blood_data/" rf1 = open(path1+filenameX_train, "rb") rf2 = open(path1+filenameY_train, "r") X_train_binary = rf1.read(bytesize*pixelnum*all_filenumber) # 画像データの格納(バイナリから整数(char型)に変換して) for i in range(bytesize*pixelnum*all_filenumber): X_train_int[i] = struct.unpack("B", X_train_binary[i]) # ラベルデータの格納 for item in rf2: y_train_int += list(item) rf1.close() rf2.close() # numpy配列に格納 X_train = np.array(X_train_int) y_train = np.array(y_train_int) # 画像を4次元配列に X_train = X_train.reshape(all_filenumber, 3, img_rows, img_cols) # 画像を0.0~1.0の範囲に変換 X_train = X_train.astype("float32") X_train /= 255 # 画像の前処理としての正規化 def normalization(X_train): X_train = X_train.reshape(all_filenumber, 3*img_rows*img_cols) for filenum in range(0, all_filenumber): X_train[filenum] -= np.mean(X_train[filenum]) X_train = X_train.reshape(all_filenumber, 3, img_rows, img_cols) return X_train normalization(X_train) # Kflodによる交差検証 kf = KFold(n_splits=5, shuffle=True) for train_index, eval_index in kf.split(X_train): X_tra, X_eval = X_train[train_index], X_train[eval_index] y_tra, y_eval = y_train[train_index], y_train[eval_index] model_weights = "/Users/satoshi/blood_data/vgg_model[%d].h5" % index index = index+1 # データの水増し(Data Augmentation) datagen = ImageDataGenerator( rotation_range=180, horizontal_flip=True, fill_mode='nearest') # 水増し画像を訓練用画像の形式に合わせる datagen.fit(X_tra) datagen.fit(X_eval) # クラスラベル y (数字の0~2)を、one-hotエンコーディング型式に変換 Y_tra = np_utils.to_categorical(y_tra, nb_classes) Y_eval = np_utils.to_categorical(y_eval, nb_classes) # VGG16モデルと学習済みの重みをロード(全結合層は除く) input_tensor = Input(shape=(3, img_rows, img_cols)) vgg16_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # 全結合層の構築 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:])) top_model.add(Dense(256)) top_model.add(Activation("relu")) top_model.add(Dropout(0.5)) top_model.add(Dense(nb_classes)) top_model.add(Activation("softmax")) # 全結合層を削除したVGG16モデルと上で自前で構築した全結合層を結合 model = Model(input=vgg16_model.input, output=top_model(vgg16_model.output)) # 図3における14層目までのモデル重みを固定(VGG16のモデル重みを用いる) for layer in model.layers[:15]: layer.trainable = False # モデルのコンパイル model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True), metrics=['accuracy']) # 過学習の抑制 early_stopping = EarlyStopping(monitor='val_loss', patience=10 , verbose=1) # 評価に用いるモデル重みデータの保存 checkpointer = ModelCheckpoint(model_weights, monitor='val_loss', verbose=1, save_best_only=True) # リアルタイムに水増し生成されるバッチ画像に対するモデルの適用 model.fit_generator(datagen.flow(X_tra, Y_tra, batch_size=batch_size), samples_per_epoch=X_tra.shape[0], nb_epoch=nb_epoch, verbose=1, validation_data=(X_eval, Y_eval), callbacks=[early_stopping, checkpointer]) # 評価に用いるモデル構造の保存 def save_model(model): json_string = model.to_json() if not os.path.isdir("vgg_model"): os.mkdir("vgg_model") json_name = "architecture.json" open(os.path.join("vgg_model", json_name),"w").write(json_string) save_model(model)
vgg16_learning.py
from __future__ import print_function import os import struct import numpy as np from keras.models import model_from_json # 各種パラメータ img_rows, img_cols = 100, 100 test_filenumber = 1 bytesize = 3 pixelnum = img_rows*img_cols # 配列の確保 X_test_binary = [0 for j in range(bytesize*pixelnum*test_filenumber)] X_test_int = [0 for j in range(bytesize*pixelnum*test_filenumber)] test_pred = [] # テスト画像の読み込み filenameX_test = "blood_01.raw" path1 = "/Users/satoshi/blood_data/" rf = open(path1+filenameX_test, "rb") X_test_binary = rf.read(bytesize*pixelnum*test_filenumber) # 画像データの格納(バイナリから整数(char型)に変換して) for i in range(bytesize*pixelnum*test_filenumber): X_test_int[i] = struct.unpack("B", X_test_binary[i]) rf.close() # numpy配列に格納 X_test = np.array(X_test_int) # 画像を4次元配列に X_test = X_test.reshape(test_filenumber, 3, img_rows, img_cols) # 画像を0.0~1.0の範囲に変換 X_test = X_test.astype("float32") X_test /= 255 # 画像の前処理としての正規化 def normalization(X_test): X_test = X_test.reshape(test_filenumber, 3*img_rows*img_cols) for filenum in range(0, test_filenumber): X_test[filenum] -= np.mean(X_test[filenum]) X_test = X_test.reshape(test_filenumber, 3, img_rows, img_cols) return X_test normalization(X_test) # 保存したモデル重みデータとモデル構造の読み込み for index in range(0,5): model_weights = "/Users/satoshi/blood_data/vgg_model[%d].h5" % index json_name = "architecture.json" model = model_from_json(open(os.path.join("vgg_model", json_name)).read()) model.load_weights(model_weights) # 各モデルにおける推測確率の計算 test_pred.append(model.predict(X_test)) test_average = np.array(test_pred[0]) # 5種類のモデルの推測確率の平均 for i in range(1,5): test_average += np.array(test_pred[i]) print(test_pred[i]) test_average /= 5 print(test_average)
vgg16_evaluation.py
15 件





 木田智士
木田智士





