精度の検証
学習に使っていない25%の画像を使って検証を行います。
import matplotlib.pyplot as plt def draw_digit3(data, n, ans, recog): plt.subplot(20, 20, n) Z = data.reshape(imagesize,imagesize) Z = Z[::-1,:] # flip vertical plt.xlim(0,imagesize-1) plt.ylim(0,imagesize-1) plt.pcolor(Z) if ans==recog: plt.title("ans=%d, recog=%d"%(ans,recog), size=8, color="c") else: plt.title("ans=%d, recog=%d"%(ans,recog), size=8, color="r") plt.gray() plt.tick_params(labelbottom="off") plt.tick_params(labelleft="off") plt.figure(figsize=(30,30)) import numpy as np import chainer from chainer import cuda, Function, FunctionSet, gradient_check, Variable, optimizers, serializers from chainer.training import extensions import argparse import random import chainer.functions as F import cv2 import time #cuda.get_device(0).use() # GPU print "test start" # 学習モデル読み込み model = CNN() serializers.load_npz("model_100", model.model) # テストデータリストファイルから一行ずつ読み込む(学習時と同じ) test_list = [] for line in open(r"../train_data/index/test.txt"): pair = line.strip().split() test_list.append((pair[0], np.float32(pair[1]))) # 画像データとラベルデータを取得する(学習時と同じ) x_test = [] # 画像データ格納 y_test = [] # ラベルデータ格納 for filepath, label in test_list: img = cv2.imread(filepath, 0) # グレースケールで読み込む x_test.append(img) #print filepath y_test.append(label) # 学習で使用するsoftmax_cross_entropyは # 学習データはfloat32,ラベルはint32にする必要がある。 x_test = np.array(x_test).astype(np.float32) y_test = np.array(y_test).astype(np.int32) # 画像を(学習枚数、チャンネル数、高さ、幅)の4次元に変換する x_test = x_test.reshape(len(x_test), 1, imagesize, imagesize) / 255 N = len(y_test) batchsize = 1 datasize = len(x_test) # 判定開始 test_start = time.time() false_count = 0 perm = np.random.permutation(N) # データセットの順番をシャッフル for i in range(0,datasize, batchsize): x_batch = x_test[[i]] # バッチサイズ分のデータを取り出す y_batch = y_test[[i]] result = model.forward(x_batch, y_batch, train=False) # 学習ではないのでtrainをFalse if (i%2==0): draw_digit3(x_batch[0], (i)/2+1, y_batch[0], np.argmax(result.data)) if np.argmax(result.data) != y_batch[0]: false_count += 1 print "{} No.{} NG! correct:{}, result:{}".format(test_list[i][0], i, y_batch[0], np.argmax(result.data)) else: print "{} No.{} OK! correct:{}, result:{}".format(test_list[i][0], i, y_batch[0], np.argmax(result.data)) print "data num:{} false num:{} accuracy={}".format(datasize, false_count, 1 - (float(false_count) / datasize)) print "test time:{}".format(time.time()-test_start)
検証.py
100%の精度で判別できています。

精度検証
まあ、元が同じ画像だからね。。
というあなたのために、低密度の方の画像をEpH4かHEK293か判定してみましょう。
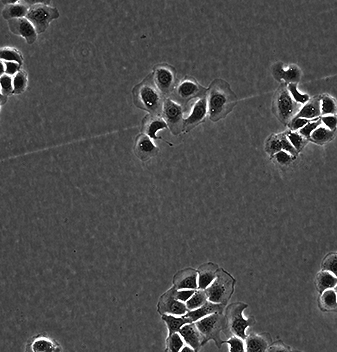
低密度EpH4

低密度HEK293
import numpy as np import chainer from chainer import cuda, Function, FunctionSet, gradient_check, Variable, optimizers, serializers from chainer.training import extensions import argparse import random import chainer.functions as F import cv2 import time import os.path import glob # 学習モデル読み込み model = CNN() serializers.load_npz("model_100", model.model) def judge(path,N): img_files = glob.glob(path) for i, filename in enumerate(img_files): img = cv2.imread(filename, cv2.IMREAD_GRAYSCALE) #print img.shape img = cv2.resize(img,(64*N,64*N)) img = img * 64.0 / cv2.mean(img)[0] height, width = img.shape x_test = [] for x in range(0,N): for y in range(0,N): clp = img[height/N*y:height/N*(y+1), width/N*x:width/N*(x+1)] x_test.append(clp) #print x_test[0].shape x_test = np.array(x_test).astype(np.float32) x_test = x_test.reshape(len(x_test), 1, 64, 64) / 255 batchsize = 1 datasize = len(x_test) # 判定開始 test_start = time.time() true_count = 0; false_count = 0; for i in range(0,datasize): x_batch = x_test[[i]] y_batch = y_test[[i]] result = model.forward(x_batch, y_batch, train=False) # 学習ではないのでtrainをFalse if (np.argmax(result.data)==0): false_count +=1 else: true_count += 1 print filename, int(100.0*float(true_count)/(true_count+false_count)),"%\t","(" ,true_count, "vs", false_count, ")\t", if true_count>false_count: print "HEK293" else: print "EpH4"
画像分類!.py
さて結果は??
judge("../not_included/*.png",5)
ジャッジ!.py
判定結果
EpH4の方が少し危なかったですが、どちらも正しく判定されています!!





 Mochizuki
Mochizuki





